According to stats in 2016, we have about 205 billion emails per day, with 600 million new tweets and 3.5 billion queries on Google per day. All such companies are working on a competitive moat with new ways of parsing and comprehending the data. Still, it is critical to keep it fresh, and whatever companies are building in the backends will be stale in a year or less. So infrastructure and hassle around clean, new, and sufficiently smart cognitive tools are the lifeblood of each of these companies. Streets rename, temperatures rise, attitudes change, and so on. Some tools and toolkits could be on the Knowledge Graphs (KGs), and the categories below. A few of my favorite things to do with the graphs are using neural nets like GAN, GCN, or RL for relation extraction. There are beautiful usage patterns from representation learning on the neural nets, where transformers and CNN, RNN, can leverage encoding models.
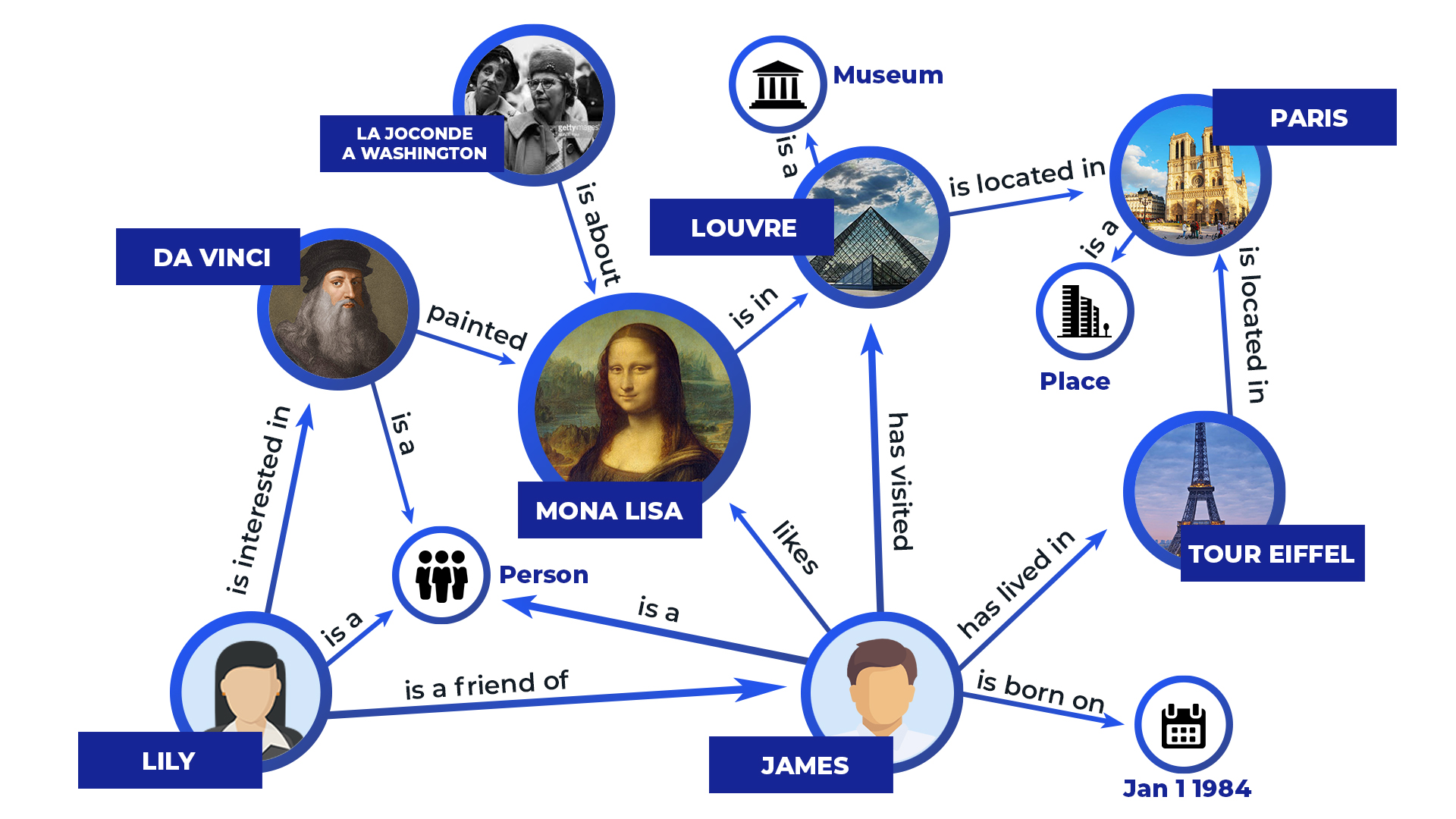
Categorization of Research on Knowledge Graphs
Data scientists are usually not participating in the collection process of the data pipelines from engineering teams, and they have to build smart assistants, models, and bots with natural language understanding on such channels. If you are in the shoes of engineers or scientists, you have to know both sides of the table to be successful as a team. For instance, if your language understanding team does not know how to reuse the production model. They could rebuild models from scratch, or the system engineering team has to decompile the model and split it into the smallest pieces of reusability. There many common problems like question answering or recommendation applications, but the Core of such systems and context or state tracking is the knowledge graph or pre-trained models that could be bought or found from big companies like Google, Facebook, or Microsoft. This year Microsoft got an exclusive license to use GPT-3 from Open AI. They trained an autoregressive language model with 175 billion parameters; such examples increase a bar for others to reach because of such a large corpus of text with specific tasks. This data set could be super critical for translation or could help answer questions with smart reasoning. Take a look more about such model from Open AI here: https://arxiv.org/pdf/2005.14165.pdf
The critical Impact of Number of Parameters on the Model Accuracy in GPT-3
Above all, the graph-based method's main aspects and advantages to context-aware recommendation systems are The User x Item x Contexts multidimensional matrix, representing any such plan's input. This data model speeds up the filtering phase and sidesteps the data sparsity challenge, which can be problematic in this situation. A proper graph model can store the multimodal results of contextual prefiltering. Precisely, in the nearest neighbor approach to prefiltering, which results in different sets of similarities among the objects or users, graphs can store several models' results by emerging the similarity nodes.
Throughout the recommendation phase, graph access patterns simplify selecting relevant data based on the present user and the current context. In the contextual modeling approach, graphs provide a suitable method to store tensors, streamlining certain operations. Furthermore, specific processes leverage a graph representation of the data (the context graph described earlier) and use graph procedures such as random walk and explicitly PageRank for building models and then provide recommendations. There are many techniques for entity extraction and linking. We could easily find multiple .NET examples of such tools like NER (named entity recognition), RL (relationships linking), Tokenization's and Compounding, N-Gram Tilling, N-Gram Splitting, Query Classifier, Matching, and Ranking. In the subsequent sections of the book, we will cover the most useful tools and provide examples. Most of the examples below will use standard configurations from the library based on tag entities with mentions. Such mentions could be Person, Organization, or Location. There are a few categories of information extraction ENAMEX, JNLPBA NUMEX, and TIMEX. For example, NUMEX is used for numbers or percents and could be retrained for your customizations on the existing NER tools. As you might already guess, TIMEX is used for time and dates. JNLPBA is NER for bioinformatics documents and cell type and other medical NLP that could be very well suited to the COVID-19 papers.
PM> Install-Package Stanford.NLP.CoreNLP
namespace Stanford.NLP.CoreNLP.CSharp {
internal class Demo {
private static void Main() {
// Path to the folder with models extracted from `stanford-corenlp-3.7.0-models.jar`
string jarRoot = @"..\..\..\resources\stanford-corenlp-full-2017-06-09";
string text = "Slava Agafonov sent an email to University of Washington";
// Annotation pipeline configuration
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref");
props.setProperty("ner.useSUTime", "0");
string curDir = Environment.CurrentDirectory;
Directory.SetCurrentDirectory(jarRoot);
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
Directory.SetCurrentDirectory(curDir);
Annotation annotation = new Annotation(text);
pipeline.annotate(annotation);
using (ByteArrayOutputStream stream = new ByteArrayOutputStream())
{
pipeline.prettyPrint(annotation, new PrintWriter(stream));
Console.WriteLine(stream.toString());
stream.close();
}
var sentences = annotation.get(new CoreAnnotations.SentencesAnnotation().getClass()) as ArrayList;
foreach (CoreMap sentence in sentences)
ArrayList tokens = sentence.get(new CoreAnnotations.TokensAnnotation().getClass()) as ArrayList;
foreach (CoreLabel token in tokens) {
object word = token.get(new CoreAnnotations.TextAnnotation().getClass());
object pos = token.get(new CoreAnnotations.PartOfSpeechAnnotation().getClass());
object ner = token.get(new CoreAnnotations.NamedEntityTagAnnotation().getClass());
object normalizedner = token.get(new CoreAnnotations.NormalizedNamedEntityTagAnnotation().getClass());
var time = token.get(new TimeExpression.Annotation().getClass()) as TimeExpression;
Console.WriteLine("{0} \t[pos={1}; \tner={2}; \tnormner={3}", word, pos, ner, normalizedner);
}
}
}
}
}
In summary, there are several toolkits for NLP, including cognitive services from the major cloud providers. In this example, we used the Standford NER engine based on Java to extract, tokenize, and split the data and mentions. You could find plenty of samples with the Stanford C# version of the CoreNLP project here: https://sergey-tihon.github.io/Stanford.NLP.NET/samples.html
Java VM uses the concept called Java bytecode (*.jar) to .NET (*.dll), so the software can read the text and convert it to the string from Java 8 to .NET Framework. Your machine will be running .NET CLR with Java Runtime engine simultaneously. It could be a bit memory intensive, so I am suggesting wrapping it around web service and put it in the Docker Container in the cloud to make it simple for scale. We will cover such things in future posts.
For now, we will remember that Stanford University used many bright students to train the models and NER with manual tagging and semi-supervised recognitions. It could also do coreference resolution and part of speed tagging. Stanford NLP is useful for dependency parsing, and it has out-of-the-box support for multiple languages but falls short here compared with libraries like SpaCy. NLP engineers use Python because of the open-source NLP toolkits such as NLTK, CoreNLP, SpaCy, and OpenNLP and machine learning algorithm libraries Scikit-Learn. If you are a .NET developer, it is tricky to use C# to do some NLP job. Though there are also Microsoft open source libraries like ML.NET, it is not a specialized NLP toolkit.
.NET Core is a cross-platform architecture that runs anywhere with ML.NET
If you are like me, you like to build scalable software without Python, an enterprise software that could scale with the system and easy for integrations with the main codebase. ML.NET is Microsoft's newest and most heavily invested library that I prefer to use when I could. If you are a heavy Google Tensor Flow user, we got you covered here with the SciSharp plugin specifically for .NET integration with the Tensor Flow library https://github.com/SciSharp/TensorFlow.NET. We will cover more ML examples of such things in the next blog posts and raise the interest for now. ML models in ML.NET are built with pipelines, which are sequences of data-loading and learning. As you might know, there are super easy scale and speed comparisons for ML at Microsoft with ML.NET that you could do side by side with Accuracy and Runtime execution. Is it something that you care about the most when it is fast and accurate? If you are a backend engineer that needs to scale the platform and optimize performance, it is critical to have a lower time for training and execution in real-time. Here are the results for the sentiment analysis problem provide higher accuracy and lower runtime: https://arxiv.org/pdf/1905.05715.pdf
ML.NET Library Performance and Speed Comparison with Other Frameworks
Data enrichment, feature selection, and fast data access
Data Enrichment is the common practice of merging external, authoritative data with first-party customer or exploratory data. First-party "raw" customer or user data may be in an unprocessed format, and incorporating more authoritative or well-organized external data can make this data much more valuable.
The standard technique is to use existing KG's to train new data or feel the gaps in a new subgraph. Like in the GPT-3 example above, Facebook used inference techniques with FBLearner Predictor for fast training and runtime predictions on social network users' everyday tasks. They could predict Like, Comment, or Share button clicks with high precision by looking at the users' features and data. Imagine if you are in a political campaign, and you know a lot of information about each user in your existing graph, now if you could potentially take a look at the likes and comments of a new user. You could predict who this person will support with sentiment analysis or other techniques.
Example of Facebook Machine Learning Pipeline
AI on graphs is no panacea, but it could give you real opportunities to automate business processes or sell ads like in the Facebook case. One important consideration is to cover multiple languages with any tools we use, so be careful before picking any NER or NLP toolkits. If you need some other language support and if it could extend later with your data.
World graph solutions for conflation, entity linking, and inference
Conflation is one of the most challenging problems to understand, and it requires being able to make the same entities merged to avoid duplication. If you are thinking of extracting surface forms in parallel, you must understand that people might have similar names, songs, or movies with similar titles. It could be a small difference in the naming in many cases, but it is possible to associate entities with duplicates if you look closer. Below are standard techniques of cosine similarity, TF-IDF, and others that could help use knowledge embeddings and names to select the right entities and avoid duplication.
Knowledge Base Candidate Selection for Entities and Relations
When you build the disambiguation and resolution pipelines, it is critical to learn the top challenges and correct them. LinkedIn showed that 17K companies in the graph were related or similar to IBM, and engineers implemented a complete auto system that solved the users' problem. It is nice to know that some things are susceptible to the error to be prepared like in the conflation case, do you want to use BiLSTM self-attention or embeddings relation prediction to clean up this mess later? There is only advice is to narrow the problem and make sure that you know what users input in the system. It is great to convert each issue to a single-turn interface where people understand the system's restrictions. The predicates of Will Smith are compiled of 100K facts taken from 40 plus websites. It could be sportsmen, actors, or politicians with the same name. There further steps to improve your data science complexity and delivery to your team that we will cover in the next paragraphs.
Overview of Machine Learning and graphs
ML Complexity for Graph Applications
But before we look deeper, we must understand our constraints and biggest challenges with integrating cognitive projects with existing processes and systems. However, now it is increasingly difficult to explain the ML model results, especially on the graph data.
Graph Persistence and Native Learning
Another exciting technique is more straightforward pathfinding in the graph or advanced feature engineering with graph native learning. Instead of a black-box model with deep learning, we could easily traverse the same graph every step of the way to see what model is trying to predict and what real-world graph nodes it is using through each step. Again, think about the chemistry field or medicine for vaccine finding a path through many different reactions or elements. Do you want to see why and how the system suggests specific multidimensional learning? Could we do that by updating the graph for better explainability? Graph native learning is doing calculations and returning the graph on top of the graph as an input, it is using connected feature engineering with the graph as input, but it is returning the same back. The process of how the model concluded is opaque, so it must be the human in the loop who will be able to analyze and provide an evidence-based explanation on things like medical recommendations. The explainer is a role for people who will explain car accidents in the case of AI autopilot.
The architecture of Graph ML Application
Graph Neural Networks were engineered with Graph Convolutional Networks (GCN) as examples in the past years. The dot product of Adjacency Matrix and Node Features Matrix represents the sum of neighboring node features that could be used for predictions like node labels, new links, or even generate a new subgraph.
Deep learning networks will be covered in the future chapters, but for now, make sure that you understand the concept of parameter-sharing with neighboring nodes in a graph. Instead of adopting recurrence, convolution, commonly used in images, is now possible on graphs. It is like a moving function on top of another process, and the result is a convolved function. GCN's (Graph Convolutions Nodes) are intriguing in many ways and could be applied to neural nets and tabular data when combined with feature graphs.
Naive ML Approach
Below we will discuss tips and Tricks While doing ML on Graphs, especially when we want to work on the graph deep learning techniques:
Combine data pipelines. We used one of the steps to optimize your channels, as described at the beginning of the chapter. Think about language understanding models that are different in terms of architecture or different data input setup. It will be a nightmare to reuse them for similar applications, like bots. When you cannot combine models as one global instance, try to simplify and combine waves of peace of the model similar to a single infrastructure with your engineering team.
Ease of use of ML models: ML methods are required to have more parameters to be more accurate as described at the beginning of this chapter, but sometimes too many parameters could make the model more complicated. Let's say linear regression will be a great approach and nearest neighbor classification, but things like SVM (support vector machine) will be too much for humans to understand. If you use too complex models, you will not be able to use them in Europe because you have to explain what the model does and how it works. As an NLP example, make sure that the graph could have a golden set dataset that you could use for validation in ML tasks. Most of your bugs with other companies and services could be related to insufficient cognitive services training data, precision mismatches, or implicit privacy violations.
Training Speed and Runtime Performance: when we have a lot of unnecessary or heavy computations with more training data, it is pretty apparent which ML techniques are faster than others. For instance, linear or logistic regression is quick because computing weighted sums from input, but things like nearest neighbor searches are going and testing against a large amount of data.
You worked very hard to get reasonable accuracy, and now the engineering team could not use your model because it is super slow. What do you do? When we discuss runtime usage or prediction speed, it is the worst issue to resolve for a data scientist. Things like nearest neighbor searches require almost no training time, but runtime is terrible, so maybe you should consider other options. We will cover this topic in further chapters and optimizations techniques on how to make sure you are well aware of your models' user experience, and you could improve it even before the training started by minimizing your available options for specific cases and using unique tactics for a production system.
Dialogue Systems over Knowledge Graphs
You probably heard about recent Deep Learning achievements in building end-to-end conversational agents without pipelines, especially chit-chat agents. An open-ended dialog system's critical element is its ability to understand everyday contexts and respond naturally by introducing relevant entities and attributes, which often leads to increased engagement and coherent interactions.
In summary, there are many constraints with the graph ML applications, and there are many best practices that we could follow to address the bottlenecks or pain with compliance at the end of the project development cycle. Describing how deep learning got the prediction or the recommendation is challenging for some ML tasks, especially when deep learning has multiple layers. So, we must follow the basic workflow and tricks to be able to explain our models later. We will cover more patterns, best practices, and scaling optimizations in the next chapters.
Recommender Engine using ML.NET
We will be working on the Movie recommender app that could be an excellent sample for ML tasks using .NET and ML.NET. We will have a few significant classes MovieRating (holds one movie rating), MovieRatingPrediction (movie rating prediction). To start this example, we will have to create a new Visual Studio Project and install Nuget packages:
- dotnet add package Microsoft.ML
- dotnet add package Microsoft.ML.Recommender
We have used Matrix Factorization in this example, but you can use two other recommendation algorithms to make predictions. The model predicts that user six would have given the movie 'GoldenEye' a rating of 3.7097, and its forecasts for the top-5 movies of user 6 are: 4.85 - Babes in Toyland, 4.73 - Strictly Sexual, 4.57 - Adam's Rib, 4.56 - White Squall, and 4.55 Guess Who's Coming to Dinner. So there is a bit of more confidence in the first two movies and pretty close scores later.
Movie Prediction Engine results for Recommender using C# and ML.NET
If you want to try your account recommendation, the full code sample: https://github.com/dotnet/machinelearning-samples/tree/master/samples/csharp/getting-started/MatrixFactorization_MovieRecommendation
The ML.NET framework could help you work on the other most common graph science algorithms, like pathfinding or similarity detection. Suppose you want to build a system to estimate heuristic link prediction. In that case, you could use relation linking and distant supervision trained on the labeled relationships with automatic clustering or partition detection.
One example of using such techniques it will be knowledge extraction from the tables in Wikipedia, where you could label some of the connections and operate a community detection algorithm to find similar entities first. After this, you could use the similarity of how nodes are alike. The library has many samples, and you could think about how you could apply them to knowledge graphs, but it should scare you to convert any regression or clustering algorithms on the graph or embeddings.
Common Graph ML Algorithms
Relation Linking over KGs
We will cover more techniques on avoiding human labor in future chapters, and we will discuss when it is required and the only way to move forward for high-quality results. Below is an example of such problems with drug discovery given a partially observed graph predicting labeled edges between nodes.
Example of Medical Graph Application
Linking of relationships is the standard-issue when we are trying to map things like attributes, relationships and use them as a context for the extraction of knowledge. It could be done using UHRS (Universal Human Relevance System) and manual annotators. This topic will be described in the further chapters, but for now, think about it like semi-supervised KG extraction for unstructured data in any domain. If you are working on the eBay product KG, cyber games graph, or sport graph for NBA (National Basketball Association), it is critical to understand the data with your team first. After this, you could play with unsupervised methods and clustering, but sometimes it is impossible. Even humans will struggle to recognize the right relationships of the unstructured text to entities. That is why we need manual labeling first and KG that could understand them later. When data is labeled, we could use techniques like distant supervision or multi-instance learning.
Summary
In the next stage, we will cover a detailed overview of ML with graphs and why we need to represent the topology, connections, and neighborhood. NER seeks to find and classify named entities in text into pre-defined categories. The most famous people, products, organizations, locations. The next chapter will go over standard best practices on graphs, including a graph. You know about hidden constraints that are easier to address at the beginning of your journey with an ML pipeline or an engine.
1. NLP Tools:
Definition: NLP tools are software libraries, frameworks, or APIs designed to process, analyze, and generate natural language text. These tools enable computers to understand, interpret, and generate human language data.
Key Components:
- Tokenization: Breaking text into individual words or tokens.
- Part-of-Speech Tagging: Identifying the grammatical parts of speech (e.g., noun, verb, adjective) in a sentence.
- Named Entity Recognition (NER): Identifying and categorizing named entities such as people, organizations, and locations in text.
- Syntax Parsing: Analyzing the syntactic structure of sentences to understand relationships between words.
- Sentiment Analysis: Determining the sentiment or emotional tone expressed in text (e.g., positive, negative, neutral).
- Text Summarization: Generating concise summaries of longer texts.
- Machine Translation: Translating text from one language to another.
- Question Answering: Providing accurate responses to user queries based on input text.
Popular NLP Tools:
- NLTK (Natural Language Toolkit): A leading platform for building Python programs to work with human language data.
- SpaCy: An open-source library for advanced NLP tasks, known for its speed and efficiency.
- Stanford NLP: A suite of natural language processing tools developed by the Stanford NLP Group.
- Hugging Face Transformers: A library that provides state-of-the-art pre-trained models for various NLP tasks.
- Google Cloud Natural Language API: A cloud-based service offering various NLP capabilities, including sentiment analysis and entity recognition.
2. Cognitive Toolkits:
Definition: Cognitive toolkits, also known as cognitive computing platforms, are software frameworks or platforms that enable the development of intelligent systems capable of mimicking human cognitive functions. These platforms often integrate various AI techniques, including NLP, machine learning, computer vision, and knowledge representation.
Key Components:
- NLP Capabilities: Integration of NLP tools and algorithms for language understanding and generation.
- Machine Learning Algorithms: Support for training and deploying machine learning models for various tasks, including classification, regression, and clustering.
- Knowledge Representation: Techniques for representing and reasoning with structured knowledge and information.
- Reasoning and Inference: Algorithms for logical reasoning and inference to derive new insights from existing data.
- Deep Learning: Support for deep learning techniques such as neural networks for processing complex data.
- Data Integration and Preprocessing: Tools for ingesting, cleansing, and transforming data from various sources.
Popular Cognitive Toolkits:
- IBM Watson: A suite of AI services and tools offered by IBM, including NLP, machine learning, and analytics capabilities.
- Microsoft Azure Cognitive Services: A collection of AI services, including NLP, computer vision, and speech recognition, provided as cloud-based APIs.
- Google Cloud AI Platform: A cloud-based platform that offers various AI services, including machine learning, NLP, and computer vision.
- Amazon AI Services: A set of AI services provided by Amazon Web Services (AWS), including NLP, speech recognition, and computer vision capabilities.
Conclusion:
NLP tools and cognitive toolkits play a crucial role in enabling computers to understand and process human language data, as well as to develop intelligent systems capable of performing complex cognitive tasks. By leveraging these tools and platforms, developers and data scientists can build a wide range of applications, from chatbots and virtual assistants to sentiment analysis systems and language translation services.
KGs, as described above, represent a stationary snapshot of our knowledge. We are taught by observing temporal patterns. While it is feasible to learn the similarity between node A and node B, it will be hard to see the parallel between node A and node C as it was three years ago.
- What type of tools might you need from toolkits? What knowledge acquisition means?
- What is a conflation, and how it is different from disambiguation? How to use cosine similarity inside NER?
- What is the difference between dialog and recommender systems?
- How we could use encoding models, and what they needed? What is the difference between temporal knowledge graphs?
- How to build a question answering system or a bot?
- Why Knowledge Vault project from Google failed?
- How to use GPUs and FPGAs instead of CPU, and why?
- What types of non-NLP applications on graphs? What is knowledge representation learning, and how is it different from knowledge acquisitions?
Further Reading
- Christopher Bishop, Pattern Recognition, and Machine Learning. Springer, 2006.
- Richard Duda, Peter Hart, and David Stork, Pattern Classification, 2nd ed. John Wiley & Sons, 2001.
- Tom Mitchell, Machine Learning. McGraw-Hill, 1997.
- Richard Sutton and Andrew Barto, Reinforcement Learning: An introduction. MIT Press, 1998
- Christopher D. Manning and Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. MIT Press.
- James Allen. 1995. Natural Language Understanding. Benjamin/Cummings, 2ed.
- Gerald Gazdar and Chris Mellish. 1989. Natural Language Processing in Prolog. Addison-Wesley.
- Frederick Jelinek. 1998. Statistical Methods for Speech Recognition. MIT Press.
- Varying neighborhood: Jumping knowledge networks (Xu et al., 2018), GeniePath (Liu et al., 2018) § Position-aware GNN (You et al. 2019)
- Pre-training Graph Neural Networks (Hu et al., 2019)
- How Powerful is Graph Neural Networks? K. Xu, W. Hu, J. Leskovec, S. Jegelka. ICLR 2019.
- http://ceur-ws.org/Vol-2456/paper69.pdf